
Desde o início de outubro de 2025, em Paris, a exposição Les gens de Paris no museu Carnavalet oferece um panorama das transformações da capital através dos seus três primeiros censos nominativos, em 1926, 1931 e 1936. É, de facto, o culminar público do trabalho de investigação realizado pela historiadora e demógrafa Sandra Brée, do laboratório de investigação histórica Rhône-Alpes (LARHRA). do CNRS.
Mas para realizá-lo com sucesso, a sua equipa contou com um projeto de investigação em inteligência artificial realizado pelo Laboratório de Computação, Processamento de Informação e Sistemas (LITIS), unidade ligada às universidades de Rouen e Le Havre Normandy, bem como ao INSA em Rouen.
Inovação em “ocerização”
Esta entidade desenvolveu de facto métodos inovadores de “ocerização”, um anglicismo forjado a partir da fórmula “OCR”: reconhecimento óptico de caracteres ou reconhecimento óptico de caracteres. As páginas dos três registros censitários, conservados nos Arquivos de Paris, foram digitalizadas. São constituídos por uma estrutura impressa de linhas e colunas com seus títulos (rua, número, sobrenome, profissão, etc.). Mas essas tabelas eram preenchidas à mão a partir de formulários domiciliares deixados nas caixas de correio dos administradores, preenchidos por estes.
Denominado POPP (Projeto de oficialização dos censos da população parisiense), o projeto LITIS visava, portanto, o reconhecimento e a retranscrição automáticos desses escritos manuscritos, a fim de fornecer bases de dados que pudessem ser utilizadas pelos historiadores. Vai ainda mais longe, como detalhou Sandra Brée durante a visita inaugural à exposição: “Os resultados obtidos foram inicialmente utilizados cientificamente, para criar infografias por exemplo. A base de dados foi depois transferida para o Arquivo de Paris e, agora, será utilizada durante décadas porque ainda há uma enorme quantidade de cruzamento de dados e pesquisas a realizar.”
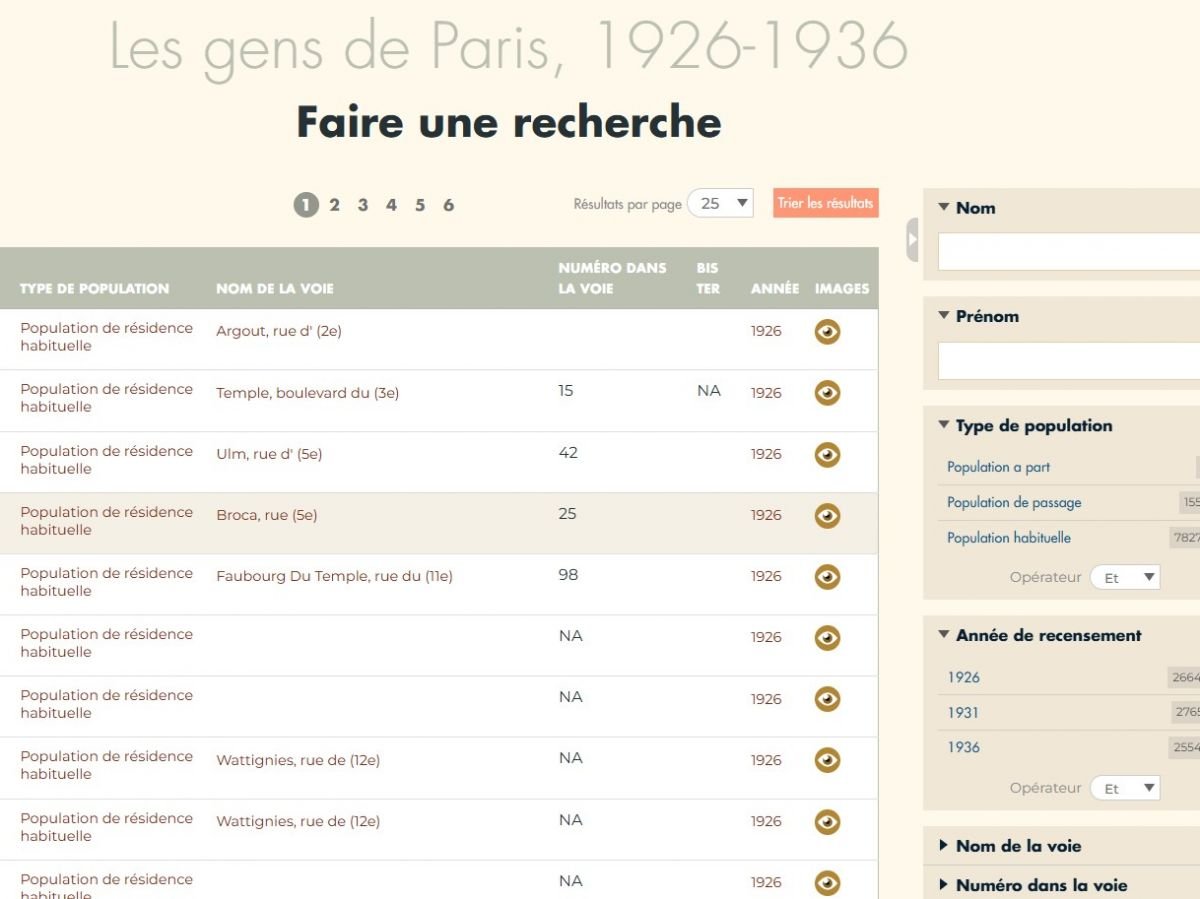
Os registros “ocerizados” estão acessíveis online no site dos Arquivos de Paris. Qualquer internauta pode consultá-los e fazer buscas por nome, endereço, ano censitário.
300.000 páginas e quase 9 milhões de nomes
O trabalho no reconhecimento automático de caracteres remonta à década de 1990, mas nenhum teve a escala deste projecto, abrangendo nada menos que 300.000 páginas e pouco menos de 9 milhões de linhas, cada uma correspondendo aos nomes e endereços dos residentes.
“O que está mais difundido, ainda hoje, é o reconhecimento da escrita impressa, nas facturas por exemplo, ou o reconhecimento da escrita manuscrita num enquadramento restrito, como os códigos postais onde as possibilidades são reduzidas”, explica Thomas Constum, especialista em aprendizado de máquina e membro da equipe POPP. De resto, a variabilidade da caligrafia coloca muitos problemas ao processamento automatizado. Cada escrita é única e as letras coladas, diferentemente da impressa, nem sempre têm o mesmo formato dependendo das sequências.
Com sua estrutura de tabela, os registros do censo permanecem mais fáceis de processar por uma IA do que por um documento com layout mais livre. Por outro lado, “o enquadramento de algumas colunas foi muito respeitado, mas outras não foram adaptadas ao uso real e o redator foi obrigado a transbordar por falta de espaço”observa Thomas Constum. Soma-se a isso o fato de que diversas pessoas, com estilos de escrita diferentes por definição, se propuseram a preencher esses documentos.
Leia tambémA estilometria envia tiques de escrita ao tribunal
O uso da autoaprendizagem
Diante do gigantismo do material, a abordagem tradicional de aprendizagem automática a partir de uma amostra de dados, neste caso 5.000 linhas de tabelas, mostrou-se inadequada devido à extrema variabilidade das escritas. Daí a escolha de aplicar o método de autoaprendizagem. O algoritmo aprende primeiro nas 5 mil linhas copiadas manualmente pelos pesquisadores e depois é testado em um volume maior: 1,4 milhão de linhas.
As previsões obtidas são então utilizadas para treinar novamente a IA, inclusive com os erros que inevitavelmente aparecem. “Isso funciona porque o grande volume de dados significa que os erros tenderão a ser compensados, porque a IA não fará necessariamente as mesmas coisas em 1926 ou 1936, ou nos mesmos bairros. explica Thomas Constum. Em suma, ela aprende com seus erros.”
O outro interesse vem do fato de que a tarefa do segundo algoritmo é mais difícil que a do primeiro porque aprende com dados transformados: “Vamos modificar o modelo para que ele utilize apenas 80% de seus parâmetros para fazer suas previsões, mas nem sempre os mesmos 80%.”
O professor e o aluno
Segue-se um modelo denominado “professor” (o primeiro treinamento) e um modelo denominado “aluno” (treinado com base nas previsões do “professor”). Então o “aluno”, por sua vez, torna-se “professor” de um novo modelo e assim por diante. O processo foi repetido cinco vezes, resultando em uma taxa de erro estimada de 4,5%. A partir daí, a historiadora Sandra Brée e sua equipe se encarregaram de corrigir manualmente os erros mais recorrentes, contando com dicionários de nomes e regras lógicas (ortografia, formato das datas de nascimento, etc.).
A taxa de erro caiu para entre 2 e 3%. É difícil fazer menos porque, nesta fase, este trabalho visaria erros pouco frequentes e envolveria um gasto de tempo desproporcional em comparação com o resultado. É por isso que, nas tabelas acessíveis ao público no site do Arquivo Nacional, o internauta pode ter dificuldade em realizar uma pesquisa sobre um determinado nome de grafia complicada (de origem estrangeira por exemplo). Ele é convidado a testar várias grafias por conta própria para encontrar a pessoa que procura. E para relatar suas próprias correções.