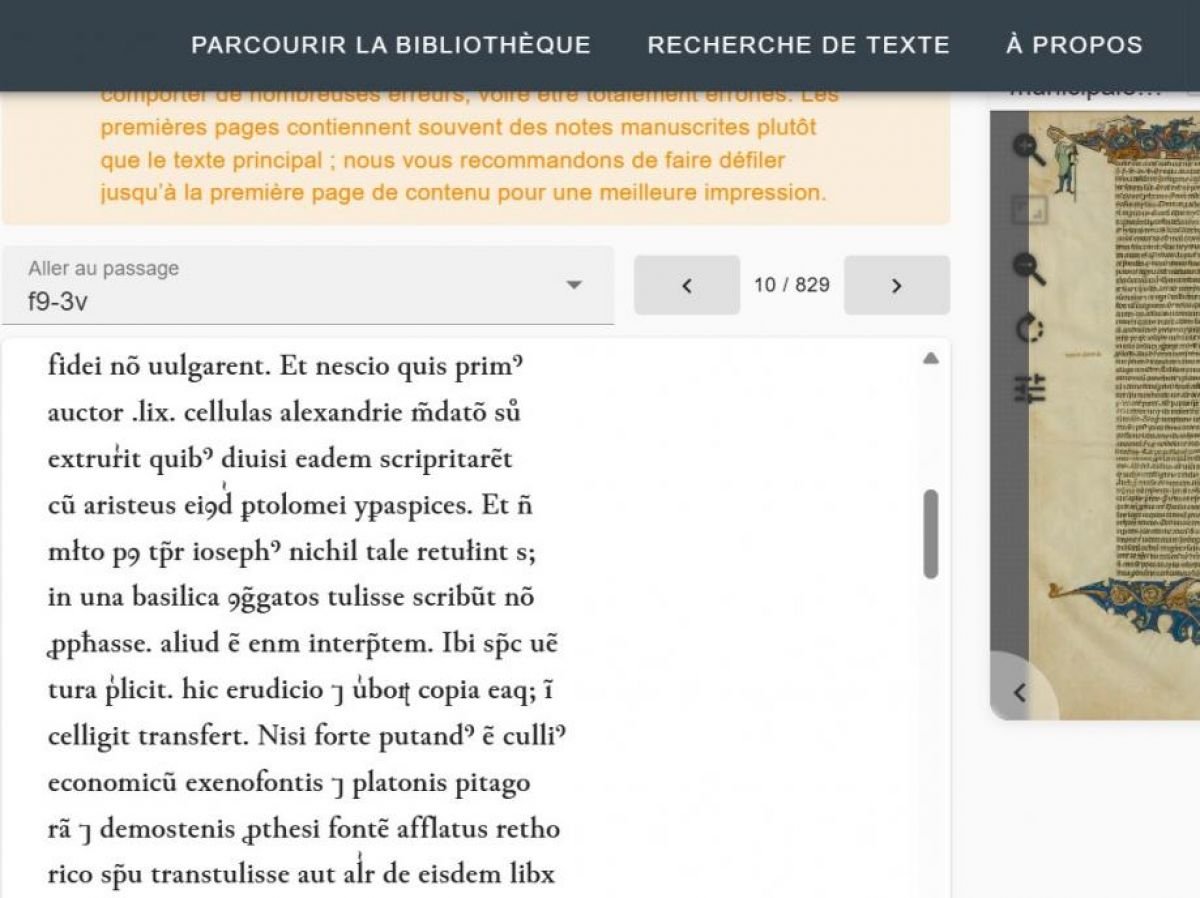

Na ARCA, biblioteca online do Instituto de Pesquisa e História dos Textos (IRHT) do CNRS, é possível consultar manuscritos medievais totalmente digitalizados. Por exemplo, 32 páginas de comentários em latim sobre os salmos datados de 12e século e pertencente à catedral de Auxerre. Rosalis é um site semelhante que hospeda digitalizações da biblioteca de Toulouse, como uma Bíblia em latim publicada em 13e século atribuído a Beda, o Venerável, monge inglês dos séculos VII e VIIIe séculos. Estes documentos, como mais de 30.000 outros, estão agora visíveis num site do Inria, CoMMA. Com uma diferença: eles podem ser baixados e visualizados na forma transcrita.
32.763 manuscritos em quatro meses
Esta transcrição foi realizada por inteligência artificial (IA), no âmbito de um projeto que reúne investigadores do Inria e filólogos (o artigo de investigação está online). O objetivo é acelerar significativamente o processo. Enquanto os humanos podem levar vários anos para transcrever um documento medieval de várias centenas de páginas, a tecnologia desenvolvida tornou possível processar 32.763 manuscritos em quatro meses!
O reconhecimento de escrita, que é mais antigo, é um verdadeiro desafio para a IA. Para uma mesma letra, uma mesma palavra, este material apresenta grandes irregularidades, que dependem tanto da época como do tipo de documento. “Notas de curso, documentos administrativos escritos às pressas serão sempre mais difíceis de processar do que o manuscrito bonito e muito regular, copiado para um nobre, até mesmo um rei. explica Thibault Clérice, pesquisador da equipe ALMAnaCH (Automatic Language Modeling and ANAlysis & Computational Humanities) do centro Inria Paris.
LLMs mal adaptados
Neste contexto, os principais modelos de linguagem atualmente em voga, como GPT, Mistral, Gemini, não são adequados: geram texto de acordo com o idioma, a predição de palavras, mais precisamente “tokens” (sequências de caracteres). Porém, na Idade Média, para o francês, ainda não existiam regras ortográficas. Você também terá que lidar com todo um sistema de abreviações. “Em latim, o pico está entre 35 e 40% de palavras abreviadas para 14e século, onde, em francês antigo, oscilamos entre 7 e 12%continua Thibault Clérice. Em documentos muito técnicos, um tratado médico por exemplo, encontramos apenas 50% das cartas presentes.
Para a equipe, o reconhecimento de caracteres tem muito mais a ver com interpretação gráfica do que com interpretação linguística. Nesta abordagem, a operação aplica-se ao sinal individual, onde um acento é um carácter autónomo (um “à” conta para que dois sinais sejam reconhecidos). Assim, de 2021 a 2022, o projeto CATMuS (Consistent Approaches to Transcribe Manuscripts) pretendeu constituir um corpus de aprendizagem e depois treinar um algoritmo com ele.
Um corpus que varia de 9e às 16e século
Durante vários anos, a equipe transcreveu 200 mil linhas de 300 manuscritos medievais diferentes, em 11 idiomas, datados de 9e às 16e século (existe outra versão do CATMus para documentos do século XVIe às 21e século). Documentos selecionados não para corresponderem aos tópicos de pesquisa uns dos outros, mas para produzir diversidade no conjunto de dados. “Respeitamos ao máximo a forma como um documento é escrito. Não resolvemos as abreviaturas, nem corrigimos a grafia, porque já deveria haver uma, insiste Thibault Clérice. Também não corrigimos erros dos escribas, como inverter duas letras.” Por outro lado, esta etapa foi uma oportunidade para uniformizar a transcrição de fenómenos particulares como abreviaturas, números escritos ou mesmo rasuras.
Este corpus permitiu então treinar um algoritmo baseado em ferramentas open source existentes, neste caso Kraken e eScriptorium, que não dependem de modelos de linguagem. “Isso evita alucinações, mas há erros de reconhecimento, como ‘ri’ transcrito ‘n’ ou vice-versa, mas tendo a preferir esse tipo de erro a uma palavra inventada no meio do texto.”
Transcrições brutas
CoMMA é o próximo passo lógico: aplicar este modelo de reconhecimento a um vasto volume de manuscritos digitalizados disponíveis na Gallica, ARCA, a plataforma Swiss E-Codices, na Biblioteca Bodleian da Universidade de Oxford (Reino Unido) e na Biblioteca Estatal da Baviera em Munique (Alemanha). A plataforma entrega transcrições brutas, sem correção posterior. Os pesquisadores, porém, estimaram a taxa de erro em 9,7%, em média, ao verificar três linhas consecutivas retiradas de 670 manuscritos.
Em última análise, os metadados de cada documento exibem a porcentagem de linhas reconhecidas corretamente. Essa pontuação pode ser muito baixa, mas geralmente ultrapassa 80 ou até 90%. “Quanto mais avançamos para a escrita cursiva, nos manuscritos tardios do corpus, mais os resultados se deterioram.alerta Thibault Clérice. Na verdade, este tipo de escrita está muito raramente presente nos dados do corpus.